Authors: Nicholas Crispino, Kyle Montgomery, Fankun Zeng, Dawn Song, Chenguang Wang
We introduce AgentInstruct to fully unleash the zero-shot reasoning abilities of large language models on general language understanding tasks. AgentInstruct combines the strength of language agents (e.g., LangChain) and LLMs (e.g., ChatGPT/GPT 3.5 Turbo). With AgentInstruct, open-source Llama-2 significantly outperforms zero-shot GPT-3.5 Turbo. AgentInstruct boosts the performance of state-of-the-art large language models by a large margin on a wide set of tasks spanning generation, classification, and reasoning.
📃 [Paper] • 💻 [Github] • 🤗 [HuggingFace] • 📌 [Blog] • 📽 [Slides] • 📋 [Poster]
Overview
We’ve made some exciting advances in the world of large language models (LLMs), such as ChatGPT, GPT-4, Bard, and PaLM 2. These language understanding powerhouses have become rock stars in various tasks, amping up deployment and adoption in many applications. The emerging abilities of LLMs, particularly in complex reasoning, have not only dominated the spotlight of recent research but also ignited huge public curiosity.
One area of LLMs we’ve struck gold is zero-shot reasoning, which has shown tremendous promise in specific task domains. But the million-dollar question is, can LLMs flex their reasoning muscles on general tasks as effectively? Well, we’re about to push that envelope further.
In our recent work, we’ve decided to boost the zero-shot reasoning abilities of LLMs in general language understanding tasks. Picture this — we construct an autonomous agent that acts as a tutor for our LLMs, guiding them step-by-step through the task. Our agent churns out task-specific instructions that piece together the reasoning process of LLMs for each task. We call this strategy zero-shot agent instructed reasoning (or AgentInstruct).
Here’s a sneak peek into our playbook. We’ve drawn inspiration from a couple of key works. First, we’ve adopted language agents, who are like little elves designed to autonomously get the job done. Only, our agent makes a twist on this, providing not the solution to the task but instructing how to accomplish it — kind of like the mastermind behind the operation. Our agent does this by gathering task-relevant knowledge from the web, and churning out high-quality, step-by-step instructions to complete tasks.
Next, we’ve leaned on the concept of chain of thought (CoT), specifically zero-shot CoT reasoning, in LLMs. This is where a task is broken down into tidbits and solved step-by-step, kind of like solving a jigsaw puzzle. We sync up this process further by feeding task-specific instructions from our agent to guide the reasoning steps. The aim here is to broaden the horizon of zero-shot reasoning abilities of LLMs to include more tasks with this combined approach.
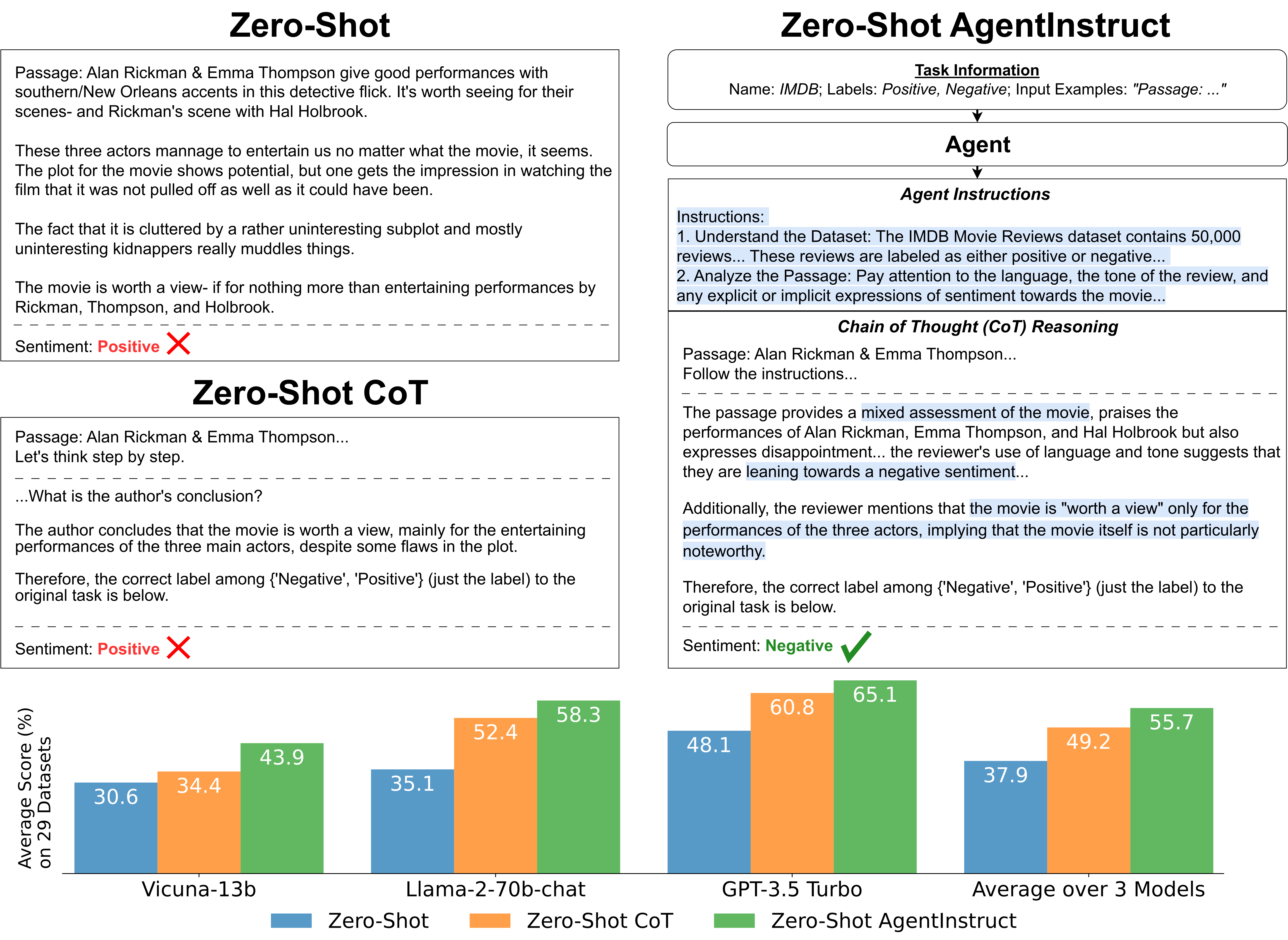
We’ve subjected our strategy to a test across a variety of language understanding tasks. And guess what? The results have been pretty great! We achieved state-of-the-art performance on 20 out of 29 datasets we evaluated using three stellar LLMs — Vicuna, Llama-2-chat, and GPT-3.5 Turbo. More importantly, our strategy resulted in a significant performance boost overall, including Vicuna-13b (13.3%), Llama-2-70b-chat (23.2%), and GPT-3.5 Turbo (17.0%), particularly in reasoning tasks.
AgentInstruct

We’re diving into zero-shot AgentInstruct, a method that employs an agent to instruct LLMs to reason toward the final prediction. More importantly, for each dataset, the instructions are generated only once. Then, these same instructions are used across all instances and models when doing inference on that dataset. We only run our agent 29 times overall, once for each of the 29 datasets, NOT on every test instance of each dataset. AgentInstruct is zero-shot as there is no training involved.
You know how we humans often rely on clear instructions to guide our thought processes when tackling a problem? Well, to make sense of, say, a movie review, instructions like “1. Understand the Dataset: … Movie Reviews dataset … 2. Analyze the Passage: Pay attention to … the tone of the review …” are exceptionally helpful. They allow us to break down the problem into manageable chunks of task-specific reasoning steps, which we can solve one by one to arrive at the final answer.
Inspired by this, we came up with a way to produce task-specific instructions that can guide the reasoning process of our LLMs. But we didn’t just want to handwrite these instructions. Instead, we built an agent to take over the task! AgentInstruct consists of two components:
-
Instruction generation: Built on ReAct’s implementation in LangChain, the agent is designed to be a high-quality synthesizer of instructions. Our agent uses GPT-4 to propose a series of thoughts, tool-based actions, and observations. The output of these actions? Our task-specific instructions! The intuition is that an agent is able to synthesize high-quality instructions with access to a wide range of existing task knowledge on the web.
-
Chain of thought reasoning: This instructs our LLMs to break down a task into simpler steps leading to the final answer, using our task-specific agent instructions as a guide.
Results


Overall, zero-shot AgentInstruct wins on 9 of the 13 generation datasets, 11 of the 16 classification datasets, and 10 of the 12 reasoning datasets. These datasets consist of datasets from the HELM benchmark and CoT reasoning datasets. We compare zero-shot AgentInstruct to standard zero-shot prompting. On each model, zero-shot AgentInstruct wins on the majority of datasets, with no less than a 13.0% increase on average. Average performance versus the zero-shot setting is best on Llama-2-70b-chat with a 23.2% improvement.
Significantly, Llama-2-70b-chat beats the performance of zero-shot GPT-3.5 Turbo by 10.2% on average across all datasets. Additionally, the 13b version of Llama-2-chat outperforms zero-shot GPT-3.5 Turbo by over 2%.
The most immediate comparison to zero-shot AgentInstruct is zero-shot CoT, as zero-shot AgentInstruct uses task-specific instructions instead of a fixed manual instruction. On average, across all three models, zero-shot AgentInstruct beats zero-shot CoT by 6.5%, with the largest growth being Vicuna-13b at 9.5%.
In particular, we look into the performance on reasoning tasks. Of our three models, the average difference between zero-shot AgentInstruct and the zero-shot setting on reasoning tasks is 31.3%, whereas the difference between zero-shot AgentInstruct and zero-shot CoT is 10.5%. As an example, we show the CoT reasoning steps from an instance of IMDB when predictions are correct.


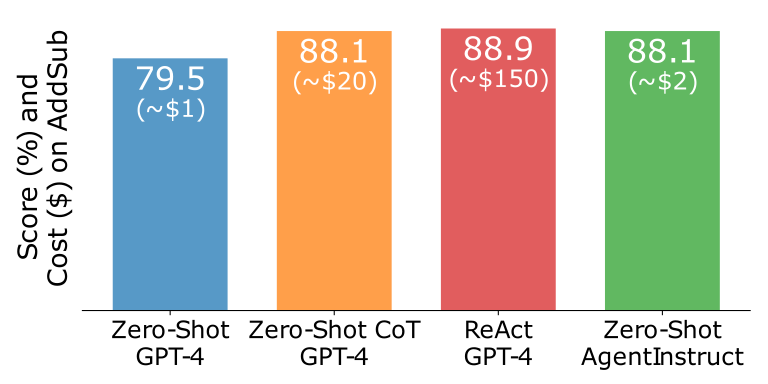
We also focus our analysis on GPT-4. We test the following methods: zero-shot, zero-shot CoT, ReAct, and zero-shot AgentInstruct. Zero-shot AgentInstruct outperforms zero-shot GPT-4 by 8.6% and ties the performance of zero-shot CoT GPT-4 for approximately one-tenth of the cost.

We also compare Llama-2-70b-chat zero-shot AgentInstruct with few-shot results. Surprisingly, zero-shot AgentInstruct reaches competitiveness with few-shot prompting.
Limitations and Safety
AgentInstruct is built on agents and language models. Similar to the base methods or models, it has its own set of limitations and can pose potential harm when misused. A notable concern is LLMs’ tendency to generate non-factual responses with a high degree of confidence. It is crucial to investigate this limitation further.
When misused, LLMs’ hallucinated responses can contribute to the proliferation of misinformation, spam, and other undesirable content. Furthermore, the mechanism exhibits several other shortcomings shared by language models, including:
- Biases and stereotypes: LLMs may inadvertently perpetuate harmful stereotypes, discrimination, and other negative consequences due to biases inherited from the instructions.
- Lack of common sense: Despite their ability to generate coherent and grammatically correct text, LLMs often lack the common sense knowledge that humans possess. This deficiency can result in nonsensical or inappropriate responses.
- Limited understanding: LLMs may struggle with grasping the context and nuances of a conversation. Additionally, they can have difficulty detecting sarcasm or irony, potentially leading to misunderstandings.
AgentInstruct has made progress towards addressing these limitations through the creation of task-specific agent instructions to guide the LLMs’ reasoning across tasks. However, it remains vital for future research to thoroughly examine and address these issues to enhance the overall performance and safety of techniques like AgentInstruct built upon language models.
Release
So far, we have released the following:
- Paper: https://arxiv.org/abs/2310.03710
- Code: https://github.com/wang-research-lab/agentinstruct
- Hugging Face: https://huggingface.co/datasets/WangLab/AgentInstruct
We recognize the heightened risk surrounding this release, as any release that increases the performance of AI systems carries some inherent danger, especially given that our approach requires no additional training to implement. However, we believe that the benefit of our research to the academic community outweighs the potential costs.
Furthermore, we understand the potential drawbacks of releasing an enhanced method for LLMs, namely concerns regarding producing disinformation and harmful content. We are exploring further methods to mitigate these risks.
License
The usage of AgentInstruct is subject to the Licenses of corresponding LLMs. Please contact us if you find any potential violations.
Further Discussion
- Data-Centric AI: We hope that our work is impactful in the ongoing debate between model-centric AI and data-centric AI. Though scaling to larger models certainly enables more sophisticated NLP tasks to be accomplished, our work suggests that it’s equally effective to modify existing weaker AI models using innovative instruction engineering techniques. Other recent publications (Alpaca, Koala, Vicuna, Dolly, and Self-Instruct) suggest that it’s also effective to train small models on high-quality instruction-following data. Both approaches avoid the risk and cost of training new, innately more powerful language models.
- Decentralization: Given concerns about centralized LLMs regarding data privacy, it’s important for open-source alternatives to exist that achieve comparable performance. Additionally, open-source alternatives offer details about model architecture and training data.
Future Directions
- Reproducibility: We plan to evaluate AgentInstruct on more benchmark datasets beyond those listed in our paper. We’ll start with the remaining HELM scenarios, then evaluate on exams that GPT-4 was evaluated on, and continue with more tasks.
- Multi-Agent: We also plan to extend the capabilities of agent instructions by enabling conversations between multiple agents like AutoGen.
- Safety: We must explore methods to mitigate the risks associated with using LLMs in conjunction with AgentInstruct, namely misinformation, bias, and harmful content.
- Evaluation: We will measure our performance on benchmark datasets using a selection of additional metrics targeting robustness, fairness, bias, and misinformation, rather than using just accuracy.
- Understanding: In addition to formalizing our method, additional work related to understanding the mechanisms behind why AgentInstruct is successful is needed.
Team
AgentInstruct was developed as a joint effort between WashU NLP Group at WashU and UC Berkeley.
Students: Nick Crispino, Kyle Montgomery, Fankun Zeng
Advisors: Dawn Song, Chenguang Wang
Acknowledgements
Our work on this project greatly depends on previous work surrounding agents and LLMs. Specifically, we would like to thank Ce Zhang and Together AI. Furthermore, this project would not have been possible had Meta/Vicuna not provided us with research access to the model weights. Finally, we extend our gratitude to OpenAI for API access to GPT-3.5 and GPT-4; it has been integral in the successful completion of this work.
Citation
@article{crispino2023agent,
title={Agent Instructs Large Language Models to be General Zero-Shot Reasoners},
author={Crispino, Nicholas and Montgomery, Kyle and Zeng, Fankun and Song, Dawn and Wang, Chenguang},
journal={arXiv preprint arXiv:2310.03710},
year={2023}
}